
CS 475 Machine Learning (Spring 2021): Assignment 4
Due on April 20th, 2021 at 11:59 PM ET
Machine Learning代写 Instructions: Please read these instructions carefully and follow them precisely. Feel free to ask the instructor if anything is unclear!
- Please submit your solutions electronically viaGradescope. Machine Learning代写
- Pleasesubmit a PDF file for the written component of your solution including deriva- tions, explanations, etc. You can create this PDF in any way you want: typeset the solution in LATEX (recommended), type it in Word or a similar program and con-vert/export to We recommend that you restrict your solutions to the space allocated for each problem; you may need to adjust the white space by tweaking the argument to \vspace{xpt} command. Please name this document <firstname- lastname>-sol4.pdf.
- Submitthe empirical component of the solution (Python code and the documentation of the experiments you are asked to run, including figures) in a Jupyter notebook
- Inaddition, you will need to submit your predictions on digit recognition and sentiment classification tasks to Kaggle, as described below, according to the competition Please report kaggle scores in the pdf submission or in the Jupyter notebook.
- Latesubmissions: You have a total of 96 late hours for the entire semester that you may use as you deem fit. After you have used up your quota, there will be a penalty of 50% of your grade on a late homework if submitted within 48 hours of the deadline and a penalty of 100% of your grade on the homework for submissions that are later than 48 hours past the
- What is the required level of detail? When asked to derive something, please clearly state the assumptions, if any, and strive for balance: justify any non-obvious steps,but try to avoid superfluous When asked to plot something, please include the figure as well as the code used to plot it. If multiple entities appear on a plot, make sure that they are clearly distinguishable (by color or style of lines and markers). When asked to provide a brief explanation or description, try to make your answers concise, but do not omit anything you believe is important. When submitting code, please make sure it’s reasonably documented, and describe succinctly in the written component of the solution what is done in each py-file.
Name:
I. Generative Models Machine Learning代写
In this section, we will work with two generative models: Na¨ıve Bayes and Mixture Models. We will explore their performance on two datasets you’re already familiar with: MNIST (the large train portion from HW2 now with binarized features) for digit classification and Consumer Reviews (from HW3) for sentiment analysis.
There will be Kaggle competitions to compare the performance of Mixture Models applied sepa- rately to MNIST and Consumer Reviews, while there will be no Kaggle component for the imple- mented Na¨ıve Bayes model. The same data, however, is used for both models and must be accessed through Kaggle.
Na¨ıve Bayes Machine Learning代写
In this problem you will implement a Na¨ıve Bayes (NB) classifier to be applied for binary (sentiment) and multi-class (digit) classification. We have not discussed Na¨ıve Bayes classifiers in class; below is the brief overview of this approach.
A generative model, as we have seen in class, assigns the label according to a discriminant rule
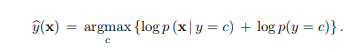
The model of class-conditional densities p (x | y = c) for each class c is typicaly parametric and fit separately to examples from each class. The model for the priors p(c) is usually simply based on counting – relative frequency of the classes in the training data. In the common scenario of balanced data where all C classes are represented with the same number of examples, the priors boil down to the uniform p(c) = 1/C and so can be ignored since they don’t contribute to the decision in (1).
A commonly used approach to regularization of such models is to limit, or penalize, the complexity of the class conditionals. In the case of Gaussian p (x | y), we can consider restricting the covariance matrices for the class-specific Gaussian models. One such restriction is to limit the covariance matrix to be diagonal for each class. If x ∈ Rd, then this means Machine Learning代写
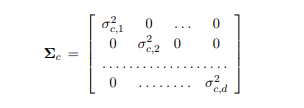
Under this restriction, the form of the Gaussian distribution for class c can be simplified:
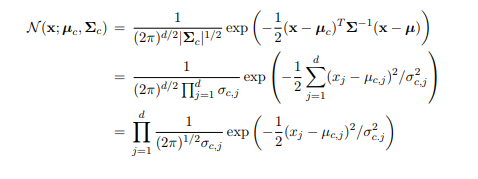
where µc,j is the j-th coordinate of µc. So, under the diagonal covariance assumption, the joint distribution of features (dimensions) of x given class c is simply the product of distributions of individual features given that class. By definition, this means that the features of x are independent conditioned on the class. Machine Learning代写
This is the Na¨ıve Bayes model. In its general form, the NB model for d-dimensional input examples x can be written as
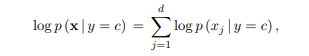
where p (xj | y) specifies the class-conditional model for a one-dimensional (scalar) value of the j-th feature of x given the class.
It’s called “na¨ıve” since this conditional independence assumption is somewhat simplistic. How- ever, it often works well in practice, both because of the regularizing effect of the independence assumption (think how many parameters does the general Gaussian model have vs. the NB Gaus- sian model) and because estimating class-conditional density is much easier computationally if it needs to be done per feature rather than jointly for many features.
In the following problem, we will use a Bernoulli distribution for each binary feature p (xj | y), where j ranges over the indices of the pixels in the input images for MNIST, or over the indices of word/bigram occurence features for the text analysis. You will need to write the code estimating the parameters of the Bernoulli distributions, and of course the NB classifier. Assume for the purpose of this assignment that the priors are equal for both/all classes, and can be ignored. Machine Learning代写
Accessible through the below Kaggle competition link is the dataset labeled datasets-hw4.h5 which is an hdf5 file similar to the one used in HW2. Within the datafile the following are accessible, note, however, that functions are provided within the utils.py file and notebook to load the data once the hdf5 file is in your working directory:
sentiment analysis/train/data
sentiment analysis/train/labels
sentiment analysis/val/data
sentiment analysis/val/labels
sentiment analysis/kaggle/data
mnist/train/data
mnist/train/labels
mnist/val/data
mnist/val/labels
mnist/kaggle/data
Here are the kaggle competition links:
- https://www.kaggle.com/c/cs-475-generative-models-sentiment-analysis
- https://www.kaggle.com/c/cs-475-generative-models-mnist
With regards to the Consumer Reviews data, your NB classifier will need to use binary features based on the occurence of bigram features (as used in HW3). With regards to the MNIST dataset, the features are (differently from in HW2) binarized pixel values 0 or 1. Code is provided to load the train/val data using the load experiment() function in utils.py, and the kaggle data is loaded using the load data() function.
Problem 1 [25 points] Use the sentiment and digit classification data described above for training (i.e. for estimating the parameters). Construct an NB classifier using ML estimate for Bernoulli parameters. Machine Learning代写
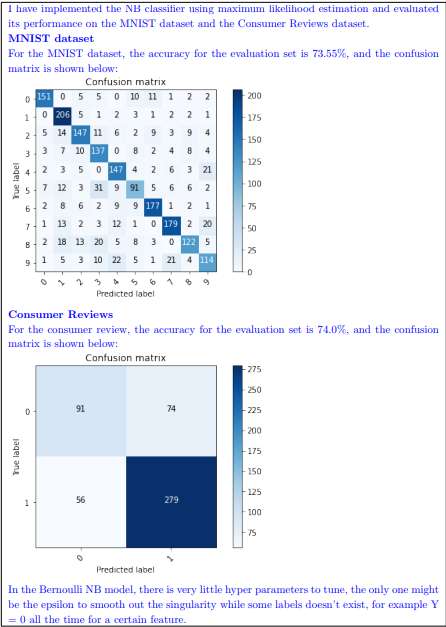
Please evaluate your trained models on the corresponding validation sets (for MNIST and Con- sumer Reviews), then report the accuracy and confusion matrix in the ipython notebook. How might you change the parameter estimation to improve this fairly “na¨ıve” model?
II. Mixture Models Machine Learning代写
In this part of the problem set we will derive and implement the EM algorithm for a discrete space, in which the observations are d-dimensional binary vectors (containing either 0 or 1). We will model distributions in this space as a mixture of multivariate Bernoulli distributions. That is,
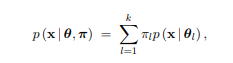
where θ = [θ1, . . . , θl] are the parameters of the k components, and the mixing probabilities π = [π1, . . . , πk]T are subject to l πl = 1.
The l-th component of the mixture is parametrized by a d-dimensional vector θl = [θl1, . . . , θld]T . The value of θlj is the probability of 1 in the j-th coordinate in a vector drawn from this distribution. Since the dimensions are assumed to be independent, given θl, the conditional distribution of x under this component is Machine Learning代写
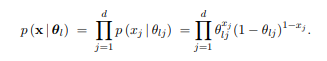
The hidden variables here are, just in the Gaussian mixture case, the identities of the component that generated each observation. We will denote the hidden variable associated with xi by zi. The EM with the model proceeds as follows. The E-step consists of computing the posterior of the hidden variables, γi,c = p (zi = c | xi; θ, π). In the M-step, we need to update the estimates of θ and π. These updates can be derived in a way similar to the derivation for the Gaussian mixture.
Problem 2 [25 points] Write the exact expression for the posterior probability
γi,c = p (zi = c | xi; θ, π)
in terms of x1, . . . , xN and the elements of θ and π.

Problem 3 [25 points] Derive the M-step updates for the multivariate Bernoulli mixture, using given γi,c values from the preceding E-step.

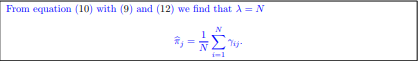
This model could be applicable, for instance, in modeling distributions of consumer reviews using binary features. In the following problem, we will apply it to the sentiment analysis task we have encountered in an earlier problem set, as well as a multi-class classification objective in MNIST
digit classification.
One method of using EM in a discriminative setting is to train a separate mixture model for each class. That is, in the context of digit classification, one EM would only see images of the digit 0 and a different EM would see each of the other digits 1–9. It is common for generative models to be trained separately for each label like this Machine Learning代写
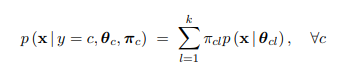
Once these are trained, a discriminative model emerges naturally by selecting the class with maxi- mum likelihood for a given sample
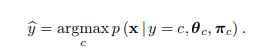
A common simplification, which you may use if you want, is to assume that one component will dominate the likelihood and thus compare the likelihoods separately for each component
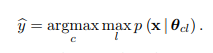
The mixing weights are in this case ignored. Note that this is equivalent to viewing all the mixtures models as a single hierarchical mixture model and then selecting the leaf component with the maximum likelihood.
Problem 4 [25 points] Implement a classifier for the aforementioned tasks based on multiple Bernoulli mixture models as described above. A new Kaggle competition has been set up, and the data as well as further descriptions are available at this link (note: this is the same link as above copied again for your convenience): Machine Learning代写
- https://www.kaggle.com/c/cs-475-generative-models-sentiment-analysis
- https://www.kaggle.com/c/cs-475-generative-models-mnist
A few practical considerations when implementing EM:
- The EM algorithm is sensitive to initialization. You may find that randomly setting your weightswill not give good A simple method that works well in practice is to randomly assign samples to a component and then calculating the corresponding means of those clusters. This may seem strange, since all components will start very close to the population mean. However, it works well in practice.
- When your means (θ) get close to 0 or 1, it can cause overfitting and One way ofsolving this problem is by deciding on an s ∈ (0, 1 ) and each time you update your means make sure that θ ∈ [s, 1 − s]. If they lie outside of this range, you simply snap them to the closest boundary value. You will have decide an appropriate value for s.
- You will need calculations of the generalform
![]()
If the values of x have large absolute values, you will run into numerical underflow or overflow as exp(xi) approach zero or infinity. In our case, we are worried about underflow, since we are dealing with events of very low probability. A common trick is to find an appropriate constant C and realize that the following is mathematically (but not numerically) equivalent Machine Learning代写
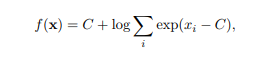
where typically C = max(x). There is a function in Python that does this: scipy.misc.logsumexp
If you find it difficult to debug your EM, a suggestion is to run it on MNIST first. This way, you will be able to visually inspect your components. If it works correctly, your components should look like prototypical digits.




