
Data algorithm
算法考试代写 本文中所提到的所有算法,无需改进优化,合理运用到爬取的数据集即可。1数据来源: 数据获取此步,没有大变动,按照上述图片执行即可。(目前已有)
本文中所提到的所有算法,无需改进优化,合理运用到爬取的数据集即可。
1数据来源: 算法考试代写

数据获取此步,没有大变动,按照上述图片执行即可。(目前已有)
2基于数据的主题模型:
拟采用BTM,以下理论部分全采用的为LDA,需要替换为BTM主题模型。

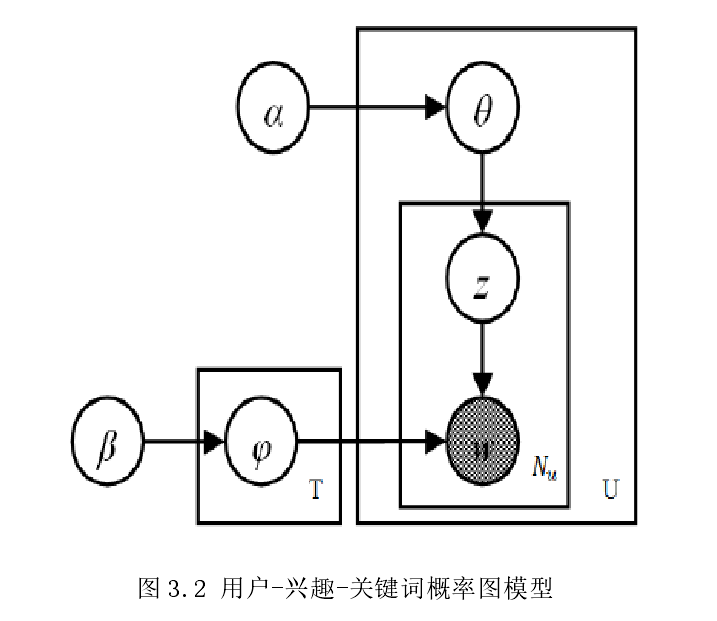
此处,该作者使用的是LDA模型。由于微博数据为短文本,拟采用BTM模型(LDA的变种,更为适合短文本模型)。红框内的内容应严格执行,蓝色方框内(包括红框内)由于是使用LDA,我打算使用的是BTM所以可以不做要求。

本步骤将爬去到的数据进行清理后,得到 用户文本的兴趣分布。
3关键词提取: 算法考试代写


本步骤得到 兴趣所对应的关键词分布
该步对应的算法流程中的 关键词集合(见下)
4整体流程(同上 本步将LDA换成BTM):




5结果与分析: 算法考试代写

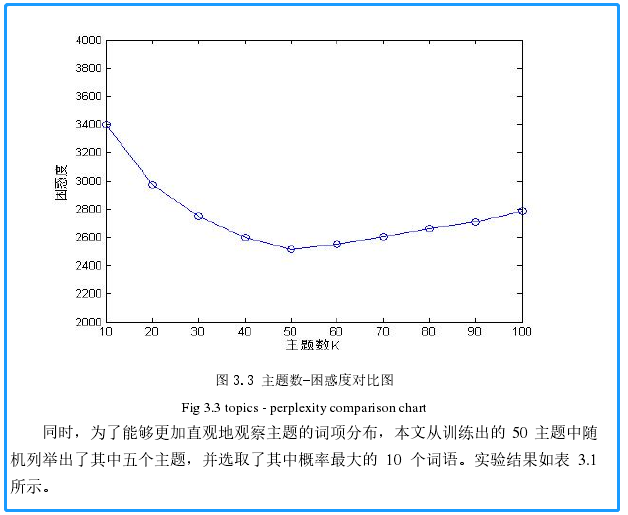
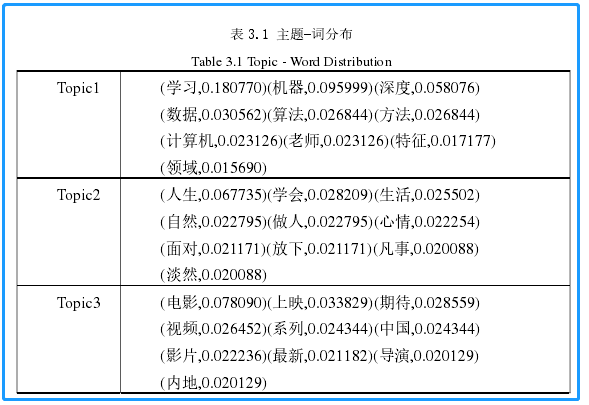
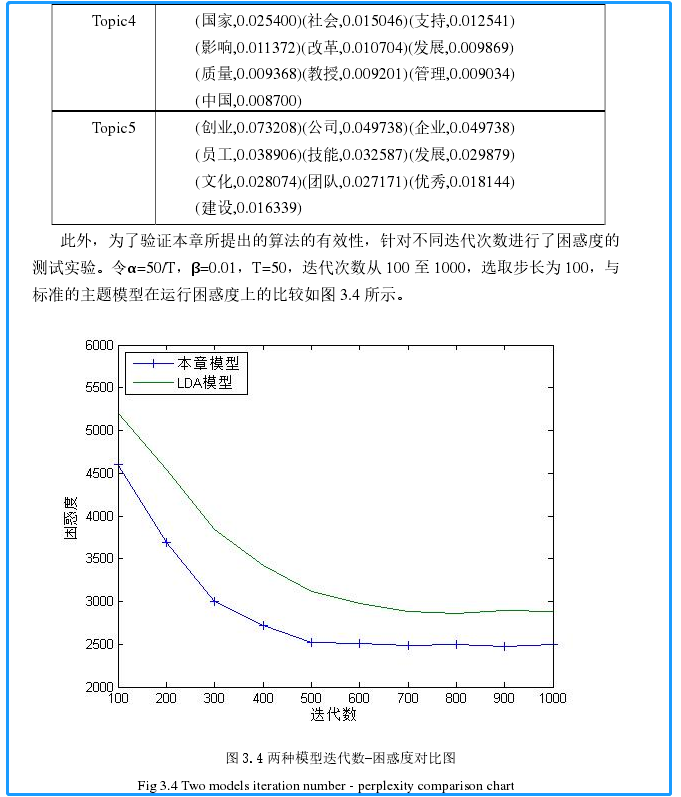
此处 无需得到结果,算法完成,注释哪里修改参数、步长与迭代次数即可。本实验中的困惑度结果如下(蓝色框内不重要,参考一下即可):



6用户兴趣分布:


此步得出D(vi,vj)即可。
!!!:所有部分,均有源码。无需更改,能用,跑通了就行。



