
更多其他:Resume代写 Assignment代写 助学金申请 Essay代写 研究论文代写 期末论文代写 毕业论文代写 论文代写
Qestion
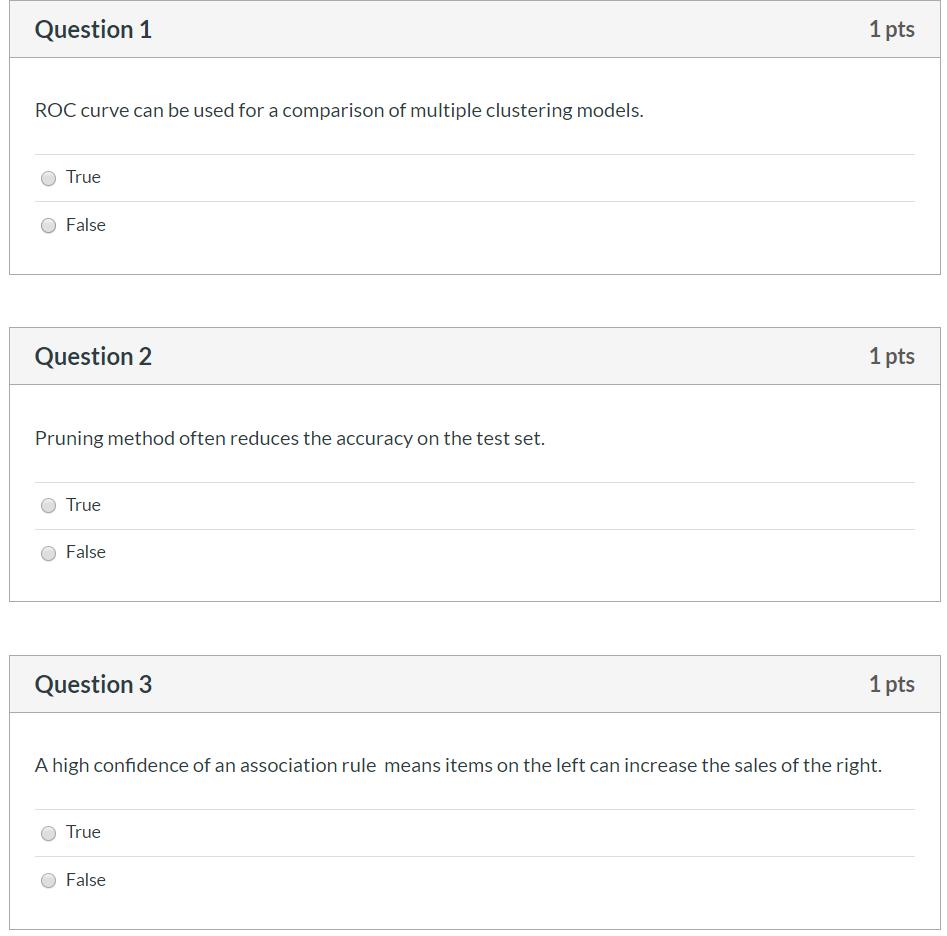
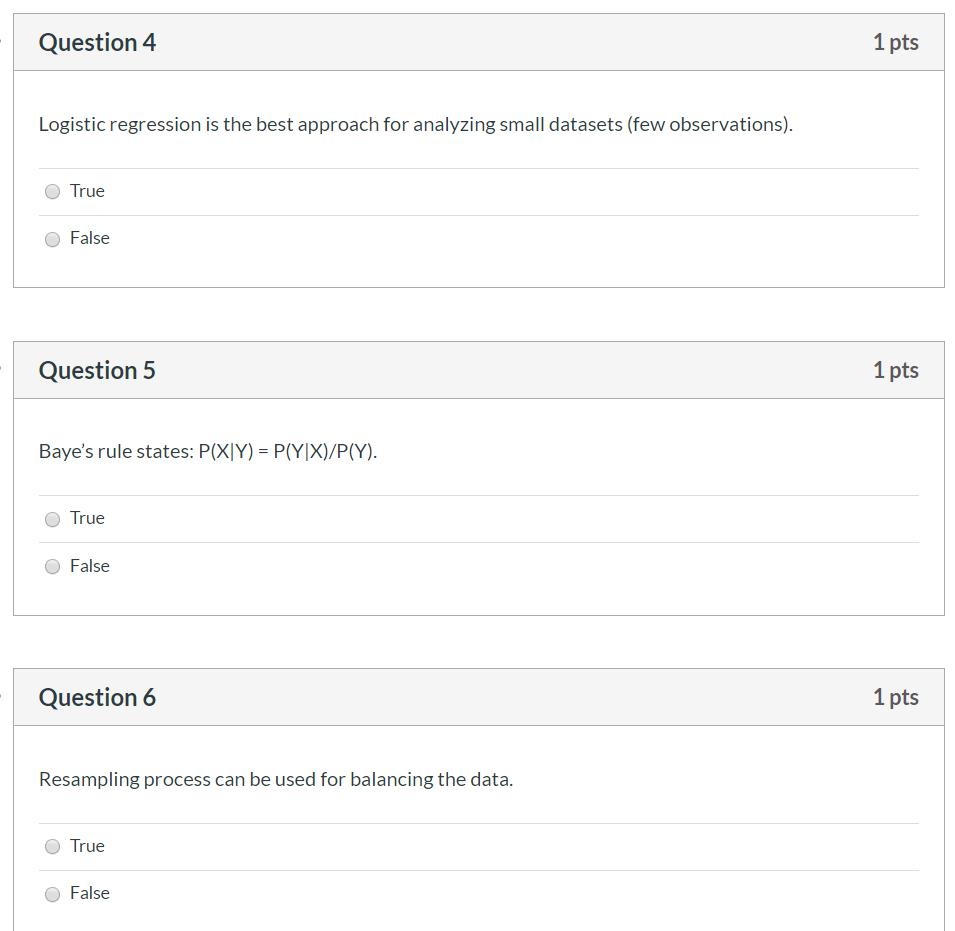
Qestion代写 Give two examples of business applications for classification.Automatic message classification and spam filtering.
1-8:FFTFFTTF
9-14: BBDBCB
15.Give two examples of business applications for classification. Qestion代写
Automatic message classification and spam filtering.
Malicious emails and links. Detecting phishing attacks becomes critical for all IT departments in organizations, considering the recent case of the Petya virus, which was distributed among corporate infrastructures through email attachments. Currently, there are many public datasets that provide labeled records of malware or even URLs that can be used directly to build classifying models to protect your organization.
Fraud detection. As fraudulent actions are very domain-specific, they mostly rely on private datasets that organizations have. For example, many banks that have fraud cases in their data use supervised fraud detection techniques to block potentially fraudulent money transactions accounting for such variables as transaction time, location, money amounts, etc.
16.Explain the difference between structured and unstructured data Qestion代写
Compared to structured data (that is, row data stored in a database, which can be expressed logically using a two-dimensional table structure), data that is not conveniently represented by a two-dimensional logical table in a database is called unstructured data. Includes office documents in all formats, text, images, XML, HTML, various reports, images and audio / video information, and more.
17.What does over-fitting mean in Machine Learning? Qestion代写
Overfitting: The root cause is too many feature sizes, too many model assumptions, too many parameters, too little training data, and too much noise, which leads to a perfect prediction of the training set by the fitted function, but the prediction of the test set of new data difference. Overfitting the training data without taking into generalization capabilities.
Solution: (1) reduce the feature size; (2) regularize and reduce the parameter value.
18.Why does it become difficult to use Exact Bayes for classification with many features?
Because the Bayesian algorithm assumes that each feature is independent of each other, when the number of features is very large, we have no way to assume that all features remain independent of each other. It is possible to violate the assumptions of the Bayesian formula.
19.What is ‘Training set’ and ‘Test set’?
Training Dataset: The data set of the internal parameters of the training model is used. Classfier directly adjusts itself based on the training set to obtain better classification results.
Test Dataset: The test set is used to evaluate the generalization ability of the model, that is, the previous model used the validation set to determine the hyperparameters, the training set was used to adjust the parameters, and finally a data set that has never been seen is used to determine whether the model is working.
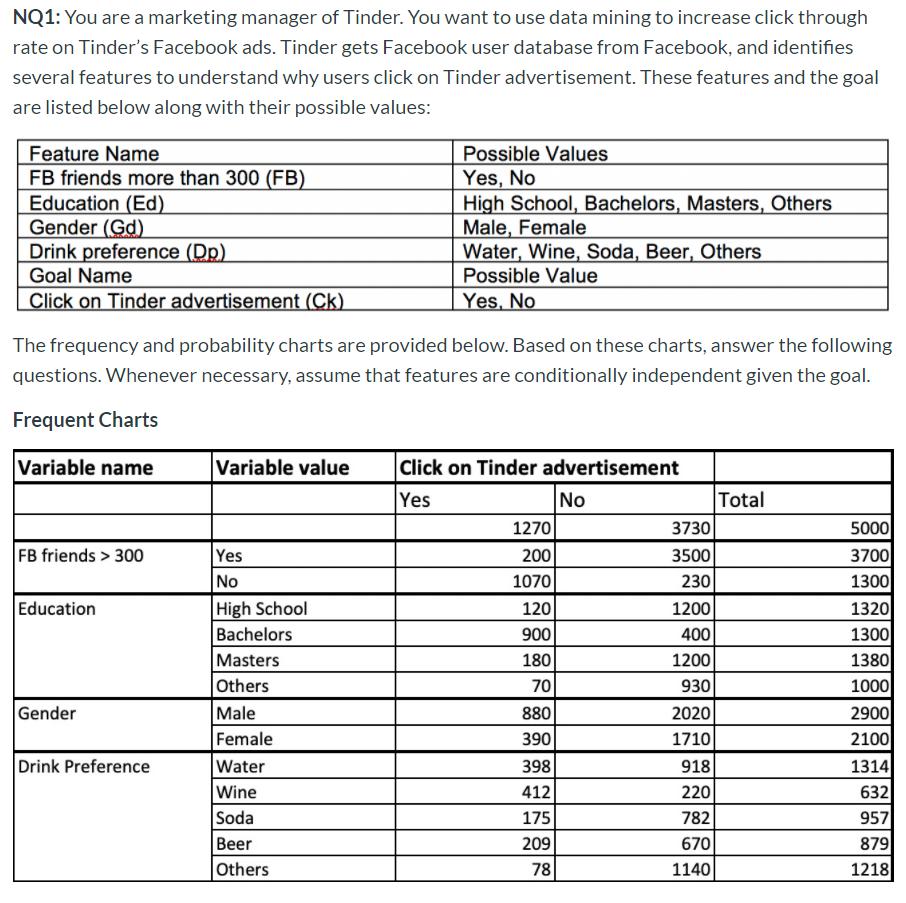
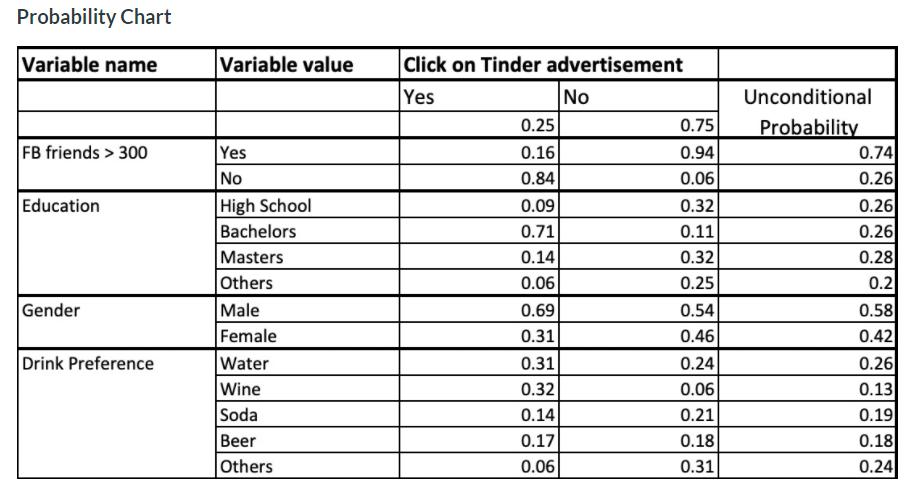

a) Qestion代写
Pr(Drink Preference = Wine| click on Tinder advertisement=Yes) =(412/398+412+175+209+78)=412/1272 = 0.32
Pr(FB Friedns > 300 = N0 | click on Tinder advertisement = Yes)
=(1070/1270) = 0.84
b)
P(HIGH| click on Tinder advertisement=Yes) = 120/(1270) = 0.09
P(HIGH| click on Tinder advertisement=No) = 1200/(3730) = 0.32
P(BACHE | click on Tinder advertisement=Yes ) = 900/(1270) = 0.71
P(BACHE | click on Tinder advertisement=No ) = 400/(3730) = 0.11
P(MAS | click on Tinder advertisement=Yes ) = 180/(1270) = 0.14
P(MAS | click on Tinder advertisement=No ) = 1200/(3730) = 0.32
P(OTHER | click on Tinder advertisement=Yes ) = 70/(1270) = 0.25
P(OTHER | click on Tinder advertisement=No ) = 930/(3730) = 0.32
Informational gain Qestion代写
H(HIGH) = -[(0.09/(0.09+0.32))*log2(0.09/(0.09+0.32))]-[(0.32/(0.09+0.32))*log2(0.32/(0.09+0.32))] = 0.7593
H(BACHE) = -[(0.71/(0.71+0.11))*log2(0.71/(0.71+0.11))]-[(0.11/(0.71+0.11))*log2(0.11/(0.71+0.11))] = 0.5687
H(MAS) = -[(0.14/(0.14+0.32))*log2(0.14/(0.14+0.32))]-[(0.32/(0.14+0.32))*log2(0.32/(0.14+0.32))] = 0.8865
H(OTHER) = -[(0.06/(0.06+0.25))*log2(0.06/(0.06+0.25))]-[(0.25/(0.06+0.25))*log2(0.25/(0.06+0.25))] = 0.7088
P(HIGH) = 0.26
P(BACHE) = 0.26
P(MAS) = 0.28
P(OTHER) = 0.2
Weighted H(Edu) = 0.26* 0.7593 + 0.26* 0.5687 + 0.28* 0.8865 + 0.2* 0.7088 = 0.7353
P(Edu) = 1270/5000 = 0.25
P(No Edu) = 1270/5000 = 0.75
H(Edu) = -[(0.25)*log2(0.25)]-[(0.75)*log2(0.75)] = 0.8113
Info Gain = 0.8113 – 0.7353 = 0.076
P(HIGH| Click = Yes) = 120/1270
P(BACHE| Click = Yes) = 120/1270
P(MAS| Click = Yes) = 120/1270
P(HIGH| Click = No) = 1200/3730
P(BACHE| Click = No) = 400/3730
P(MAS| Click = No) = 1200/3730
P (Male| Click = Yes) = 880/1270
P (Male| Click = No) = 2020/3730
P(FB>300| Click = Yes) = 200/1270
P(FB<300| Click = Yes) = 1070/1270
P (Female| Click = No) = 1710/3730
P (Female| Click = Yes) = 390/1270
P(FB>300| Click = No) = 3500/3730
P(FB<300| Click = No) = 230/3730
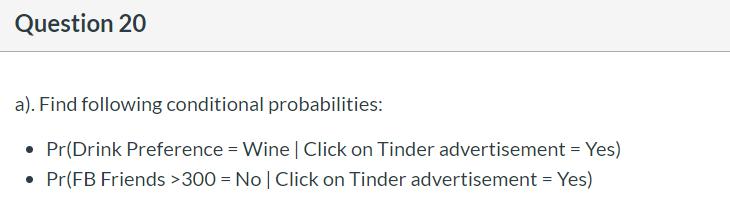
Incident 1:
![]()
Pr[E|Click = Yes] = (120/1270*880/1270*200/1270*0.25)/Pr[E] = 0.0026/Pr[E]
Pr[E|Click = No] = (1200/3730*2020/3730*3500/3730*0.75)/Pr[E] =0.1226/Pr[E]
Pr[Yes|E] = 0.0026/(0.0026 +0.1226) = 0.0208
Pr[No|E] = 0.1226/(0.0026 +0.1226) = 0.9792
Incident 2:

Pr[E|Click = Yes] = (900/1270*880/1270*1070/1270*0.25)/Pr[E] = 0.1034/Pr[E]
Pr[E|Click = No] = (400/3730*2020/3730*230/3730*0.75)/Pr[E] =0.0027/Pr[E]
Pr[Yes|E] = 0.1034/(0.1034 +0.0027) = 0.9746
Pr[No|E] = 0.0027/(0.1034 +0.0027) = 0.0254
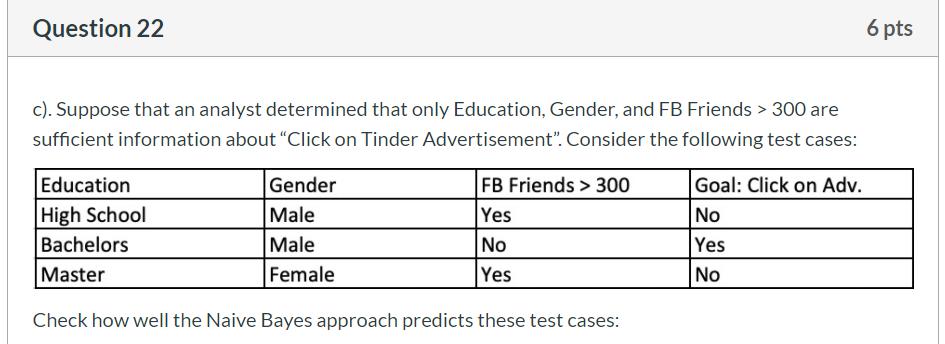
Incident 3:
![]()
Pr[E|Click = Yes] = (180/1270*390/1270*200/1270*0.25)/Pr[E] = 0.0017/Pr[E]
Pr[E|Click = No] = (1200/3730*1710/3730*3500/3730*0.75)/Pr[E] =0.1038/Pr[E]
Pr[Yes|E] = 0.0017/(0.0017 + 0.1038) = 0.0161
Pr[No|E] = 0.1038/(0.0017 + 0.1038) = 0.9839

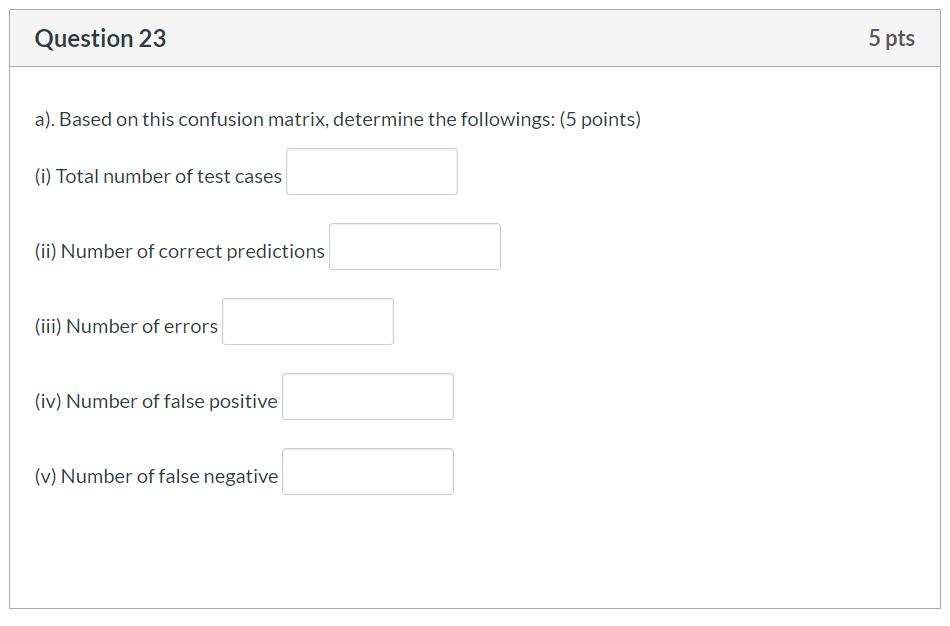
1. 1506
2. 1329
3. 177
4. 129
5. 48

Overall Accuracy= 1329/1506 = 0.8825
Stratified:
Accuracy of “Positive” = 317/ (317+48) = 0.8685
Accuracy of “Negative” = 1012/ (1012+129) = 0.8869

Because in the prediction of diabetes, the sample is very uneven. False positive means that non-diabetic patients are predicted to be diabetic patients, and false negative means that the diabetic patients are predicted to be non-diabetic patients.
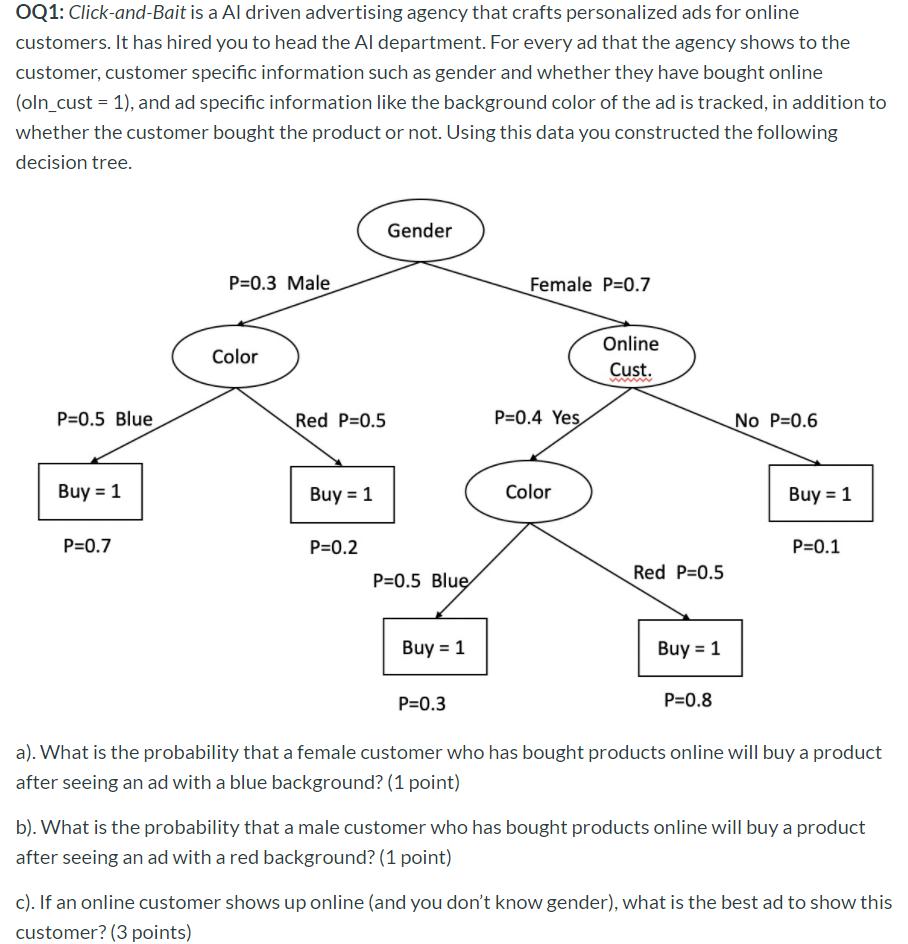
a)
Pr(Buy = 1| Gender = F, Online Customer= Yes, Color = B) = 0.7*0.4*0.5*0.3= 0.042
b)
Pr(Buy = 1| Gender = M, Online Customer= Yes, Color = R) = 0.3*0.5*0.2*1= 0.03
c) Qestion代写
Pr(Buy = 1| Gender = X, Online Customer= Yes, Color = B) =
Pr(Buy = 1| Gender = F, Online Customer= Yes, Color = B) + Pr(Buy = 1| Gender = M, Online Customer= Yes, Color = B)
=0.7*0.4*0.5*0.3 + 0.3*0.5*0.7 = 0.063
Pr(Buy = 1| Gender = F, Online Customer= Yes, Color = R) + Pr(Buy = 1| Gender = M, Online Customer= Yes, Color = R)
=0.7*0.4*0.5*0.8 + 0.3*0.5*0.2 = 0.142
Red is the best ad to show.

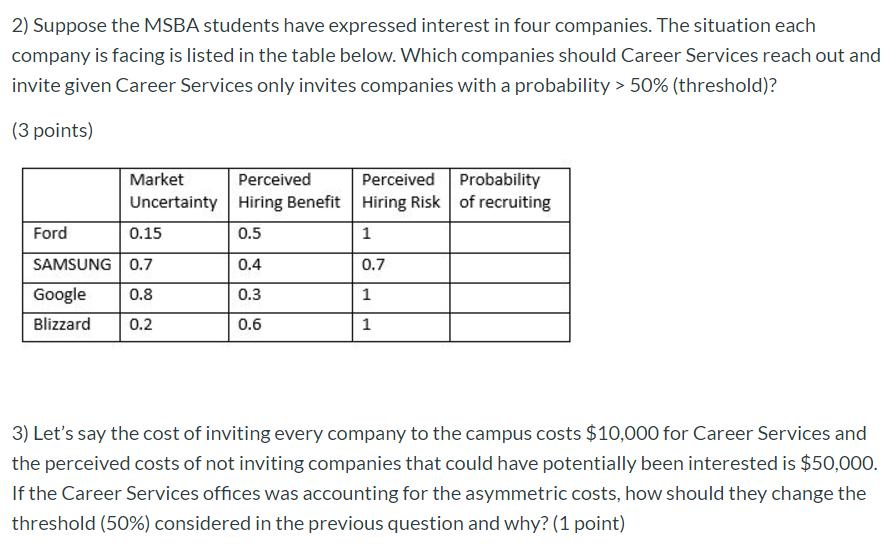
1: Market Uncertainty
2:
P(Ford) = ()/(1+) = 0.4721912270674566
P(SAMSUMG)=
()/(1+) = 0.6058593408947703
P(Google)=
()/(1+) =
0.5845548447921973
P(Blizzard)=
()/(1+) =
0.4899013735104882
SAMSUMG and Google
3: change the threshold to 60%
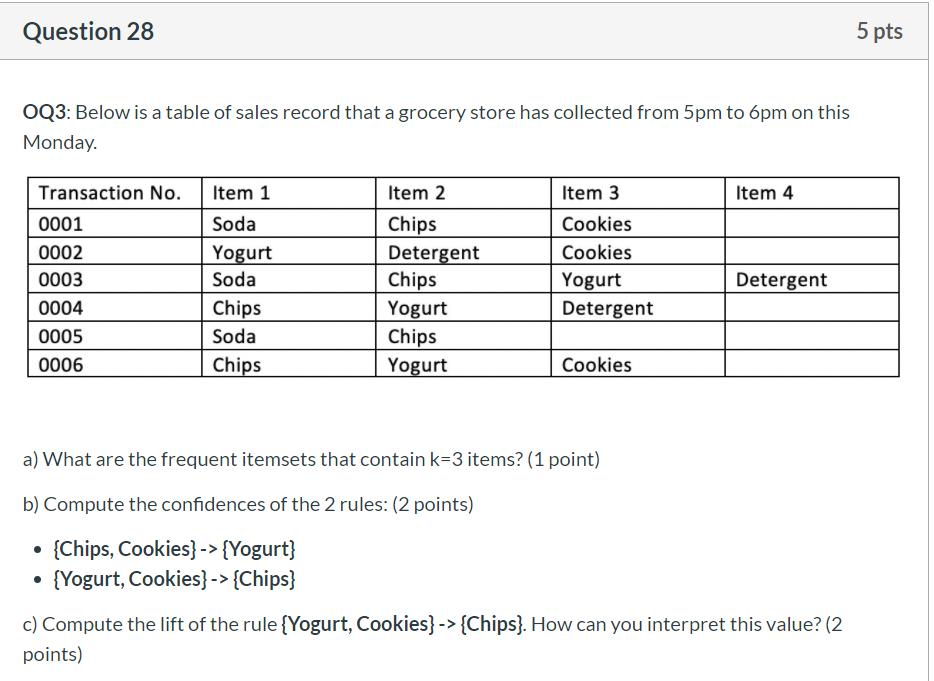
a)There are 3 frequent itemsets:
{Soda,Chips,Cookies}, {Chips, Yogurt,Detergent}, {Chips,Yogurt,Cookies}
b) confidence = (Chips,Cookies,Yogurt)/(Chips,Cookies) = 1/2
confidence = (Yogurt,Cookies,Chips)/(Yogurt,Cookies) = 1/2
c) Lift = confidence/Benchmark confidence of Chips = (1/2) / (5/6) = 0.6
Since the lift is 0.6, which is less than 1, indicating the worse rule. So buying Yogurt and Cookies together reduces the sales of Chips. Buying Yogurt and Cookies together is not a good predictor for buying Chips.
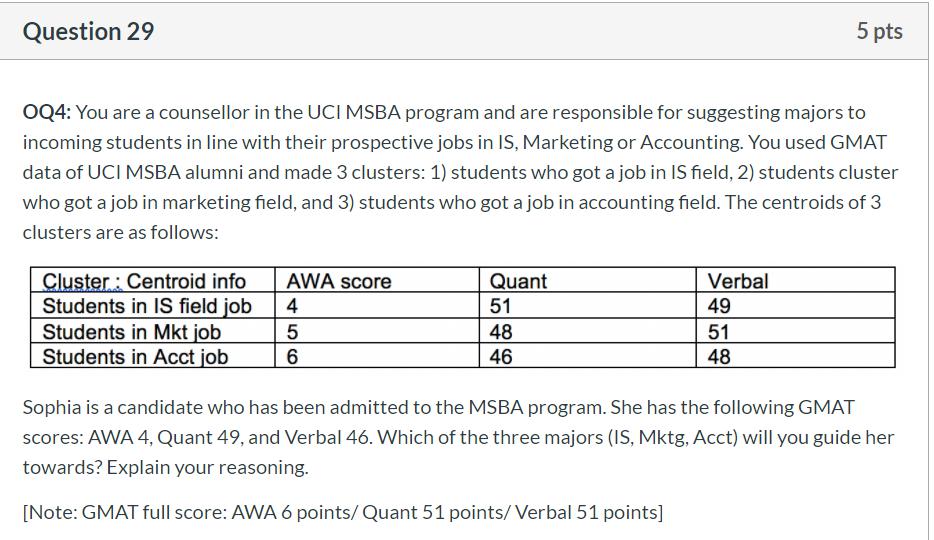
29: Qestion代写
IS Distance = sqr[(4-4)^2+(51-49)^2+(49-46)^2] = 3.6056
Mkt Distance = sqr[(5-4)^2+(48-49)^2+(51-46)^2] = 5.1962
Acct Distance = sqr[(6-4)^2+(46-49)^2+(48-46)^2} = 4.1231
Sophia is close to IS field job.



您必须登录才能发表评论。