
DEPARTMENT OF MANAGEMENT SCIENCE
MSCI212: STATISTICAL METHODS FOR BUSINESS
BUSINESS代写 You should have already worked through the ‘Brief Introduction to IBM SPSS’ document BEFORE the workshop, and you should…
Week 2 Workshop
- You should have already worked through the ‘Brief Introduction to IBM SPSS’ document BEFORE the workshop, and you should have it to hand as a useful reference.
- This workshop is designed to give you practice in using basic SPSS commands and making sense of the output.
- In Task 5 you are asked to consider which of your ‘findings’ for your sample (of 100 households) are also likely to be true for the full population (of 1140 households). This is called ‘inference’ and is an important issue for much of the course.
- You should also take the chance to practice saving your analyses for inclusion in a management report (after some editing), for instance by copying and pasting from the SPSS output Viewer to MS 0Word, as was described in the Week 0 Workshop.
__________________________________________________________________________
The SPSS data file ‘CitySuburb.sav’ contains data on income (first and second), family size and whether or not the family owns or rents their accommodation collected on 1140 households in a suburb of a particular city.
You are interested to investigate the income levels, family sizes, and ownership levels, and whether there are any relationships between the variables. However, it would be too expensive for you to gather data on all 1140 households. Instead you are going to have to do make do with sample of 100 households.
Preliminary Task BUSINESS代写
Open the data file ‘CitySuburb.sav’ in SPSS.
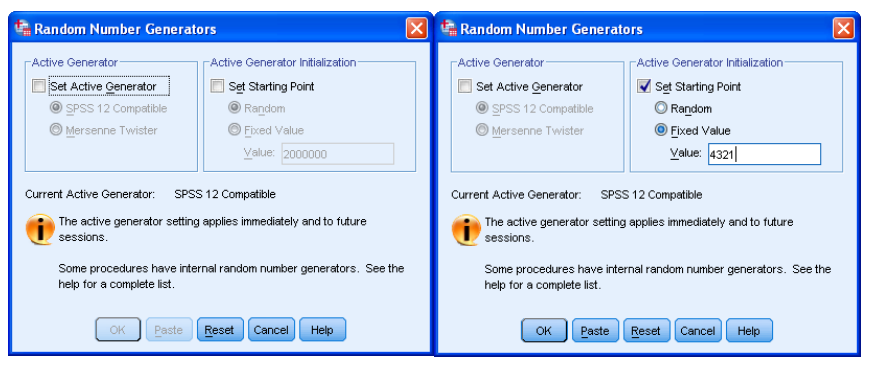
To ensure that you select a different random sample of 100 than other people in your workshop, you need to specify a unique starting point for the SPSS random number generator. Use <Transform><Random Number Generators> to get the menu on the left. Click on ‘Set Starting Point’ and on ‘Fixed Value’ and type in the last four digits of your library card as your unique ‘Value’ (e.g. below assumes the last four digits are 4 3 2 1). Click on [OK]:
Task 1:
Now draw your sample of 100 households from the suburb, using <Data><Select Cases> as below.
- Use <Data><Select Cases> to get:
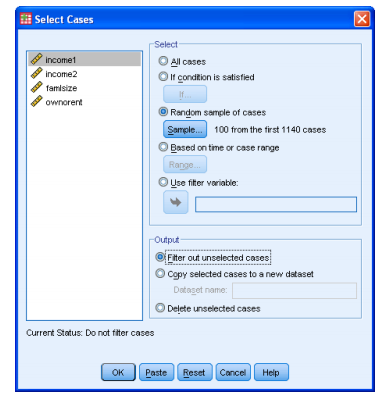
2.Highlight ‘Random sample of cases’, and then click on [Sample] to get:
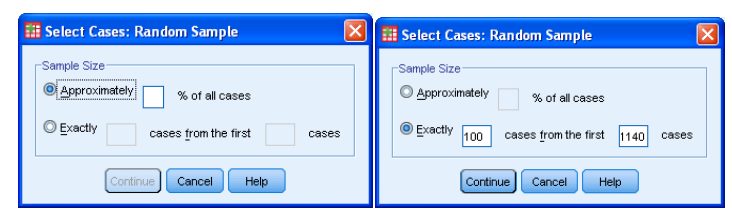
3.And click on [Continue] to get:
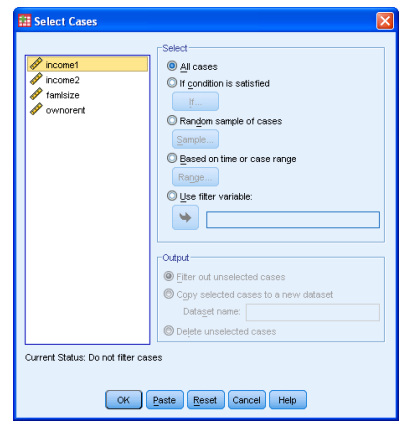
4.Click on ‘Delete unselected cases’ and click on [OK] and your data file now holds just your unique sample of 100 households.
- Save this unique sample with a different filename to the original, e.g. MySample4321, using <File><Save As> in the obvious way.
- Compare your sample with your neighbours. They should be different.
Task 2: BUSINESS代写
The four variables in the dataset are:
INCOME1: Income of the principal wage earner;
INCOME2: Income of the secondary wage earner;
FAMLSIZE: Family size;
OWNORENT: 1=own, 0=rent.
Investigate each of the four variables in your sample using appropriate descriptive methods.
Note down your main findings.
Task 3:
Look for relationships between pairs of variables in your sample using appropriate graphical methods. What are your main findings?
Task 4: BUSINESS代写
Use <Transform> <Compute Variable> to calculate the ‘Total Income’ for each household (note that SPSS will not allow you to include spaces in the name of your variable, but you can include underscores to create sensible names, e.g. Total_Income.
Investigate whether Total Income is related to Family Size in your sample.
Task 5:
Discuss and decide which of the patterns/features noted in this sample (of 100) you think are also likely to be true of the full population of 1140 households?



