
MAT 128B: Project II: Using algebraic methods for optimization:
backpropagation neural networks
Project代码代写 In this project we are going to implement a neural network to recognize hand written digits. As in the previous project you…
In this project we are going to implement a neural network to recognize hand written digits. As in the previous project you are expected to write a fifinal report explaining how you organized your research group, the algorithms you used, the code you wrote, mathematical derivations (if needed), results and conclusions from your study.
Remember to describe how you are splitting the task with your team members and provide evidence you are using Github.
Data Set Project代码代写
- i.- MINST data base Read pages 179-180 in Greenbaum and Chartier. A neural network needs a training data set that you will use to tune up the parameters of the network and a test set. Details of the data base are given in Greenbaum and Chartier and the data set can be downloaded from the book’s webpage.
- ii.- Plot digits. Implement a program that reads digits from the data base (see Fig. 4). Plot a couple of examples of the data base to convince yourself that the program is working. Compute the average digit as explained in problem 17a, plot them and compare them with those in page 180. These three examples should help you make sure that your program is working properly.
- iii.- A neuron. The implementation of a neuron is shown in Fig. 1. Each neuron consists of a set of weighted connections, and an internal activation function. Assume that a neuron has n input connections (from the data input or from other neurons). We will call the inputs {O1, …, On} and the input weights {w1, …, wn} . The value NET is calculated as explained in the fifigure and is the input of an activation function F (explained in Figure 2). Your next task is to implement a neuron where F is given on top o Fig. 1 and in Fig. 2.
We will consider the activation function to be the sigmoidal (logistic) function shown in Fig. 2. Notice that its derivative has a niceProject代码代写 expression in terms of the OUT value. (Verify that this expression is correct and include it in your report). Analyze this logistic function. What is going to be the output of the activation function for small vs large value of NET ? What other functions can you use and what would be the effffect between input and output? Project代码代写
- iv.- Multilayer Network Figure 3 shows the structure of a network with one input layer, one output layer and one hidden layer. The last layer in the fifigure (labeled as TARGET) is not part of the network but instead contains the values of the training set against which we are comparing the output. The INPUT LAYER does not perform calculations, it only takes the values from the data (See Figure 4). Neurons in the HIDDEN and the OUTPUT layer contain NET and OUT (as indicated above). The values wi,j is the weight connecting neuron i in layer 1 with neuron j in layer 2. The
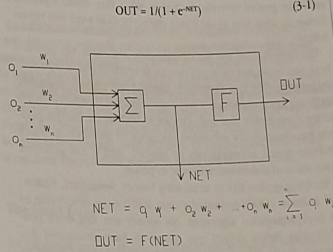
Figure 1: Structure of a neuron in the neural network. Given a set on inputs (to the neuron) and weights. The neuron fifirst computes the value NET. The fifinal output of the neuron will be given by the image of NET by the activation function F
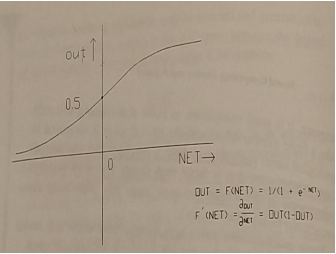
Figure 2: The activation function. The activation function can be any (bounded) difffferen-tiable function
output layer will produce OUTPUT that will be compared against the TARGET value. (Remember that we will be training the network, that means we know the input and output values). For instance, if we input the pixels for number fifive we will expect the network to output the number fifive. This will be compared with the target number fifive. The error can be encoded as 0 or 1 based on whether the network got it right or wrong. The network in Fig. 3 has only two layers (one hidden and one output) but a useful network will need more layers and more networks per layer. Implement a network with a variable number of hidden networks (and neurons per layer) in which each neuron has the structure explained above.
- v.- Initializing the network Initialize the network by assigning a random (small) number to each weight wi,j .
- vi.- Training the network A network will learn by iteratively adapting the values of wi,j . Each input is associated to an output. These are called training pairs. Follow these steps (i.e. general structure of your algorithm)
– Select the next training pair (INPUT, OUTPUT) and apply the INPUT to the network
– Calculate the output using the network Project代码代写
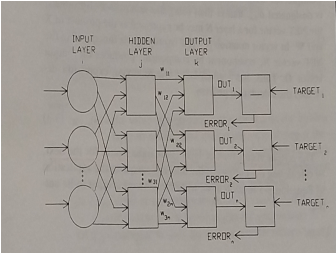
Figure 3: Multilayer network. Networks will have one INPUT, one OUTPUT layer and several HIDDEN layers. The number of layers and neurons per layer should be adjusted to the specifific problem
– Calculate the error between the network’s output and the desired output
– Adjust weights in a way that minimizes the error
– Repeat steps above for each training pair Project代码代写
Calculations are performed by layers, that is all calculations are performed in the hidden layer before any calculation is performed in the output layer. The same applies when several hidden layers are present. The fifirst two steps above are called forward pass and the second two the reverse pass.
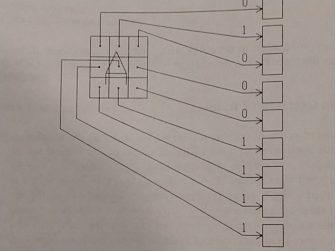
Figure 4: Structure of the INPUT layer for digit recognition
Forward pass: Notice that the weights in between layers of neurons can be represented by the matrix W and that if X is the input vector, then NET = XW and the output vector is O = F(NET). The output vector will be the input vector for the next layer.
Reverse pass. Adjusting the weights of the output layer: The ERROR signal is produced by comparing the OUTPUT with the TARGET value. We will consider the training process for a single weight from neuron p in the hidden layer j to neuron q in the output layer k (See Fig. 5). First we calculate the ERROR (=| T ARGET − OUT |) for that output neuron k. This is multiplied by the derivative of the activation function for neuron k .
δ = OUTq,k ∗ (1 − OUTq,k)(ERROR)
This value is further multiplied by the OUTp,j of the neuron p in hidden layer j and a training rate coeffiffifficient η ∈ [0.01, 0.1]. The result is added to the weight connecting the two neurons. Project代码代写
∆wpq,k = η ∗ δq,k ∗ OUTp,j ;
Therefore the confifiguration of the output layer will change for the next training set as follows
wpq,k(n + 1) = wpq,k(n) + ∆wpq,k
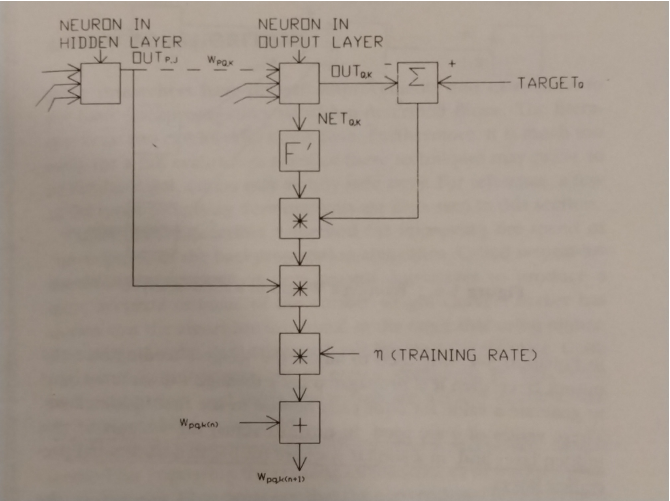
Figure 5: The training of each weight combines OUT values from the output and input neurons. The vertical line indicates the calculations that are needed to modify each weight
Reverse pass. Adjusting the weights of the hidden layers: Backpropagation will train the hidden layers by “propagating” the error back and adjusting the weights on its way. The algorithm uses the same two equations as above for wpq,k and wpq,k(n+ 1) however the value of δ needs to be computed difffferently.
The process is shown in Figure 6. Once δ has been calculated for the output layer it is used to compute the value of δ for each neuron.
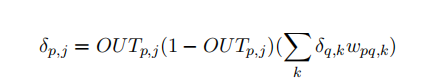
It is important to realize that all the weights associated with each layer must be adjusted moving back from the output to the fifirst layer.
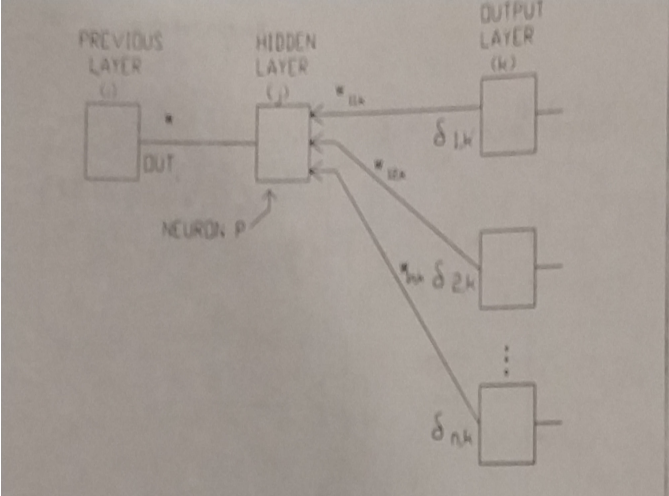
Figure 6: The training of each weight requires a new calculation of δ Project代码代写
In matrix notation this is written as follows: If Dk is the set of the deltas at the output layer, Wk the set of weights at the output layer and Dj the vector of deltas for the hidden layer in the previous Fig. 3
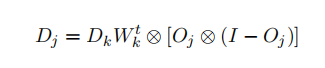
where ⊗ is defifined to indicate the component-by-component multiplication of the two vectors. Oj is the output vector of layer j and I is the vector with all components equal to 1. Show that this last formula is correct.
- vii.- Dependence on parameters The learning of the network (i.e. the minimization of the error) will depend on the number of layers, the number of neurons per layer, and for fifixed values of these two parameters the network will also depend on the size of the training set. Set up a study in which you change the values of these parameters and report the error(s) you obtain (you will obtain an error for the training set and another for the test test–which should be very similar to each other provided the test and training set are similar enough).
References Project代码代写
– P.D. Wasserman. Neural Computing: Theory and Practice. Van Nostrand Rein hold



