
DEPARTMENT OF MANAGEMENT SCIENCE
MSCI212: STATISTICAL METHODS FOR BUSINESS
统计方法代写 To ensure that you select a different random sample than other people. You need to specify a unique starting point…
Week 4 Workshop
Preliminary Task (Same as in Workshop 2)
To ensure that you select a different random sample than other people. You need to specify a unique starting point for the SPSS random number generator. To do this, use <Transform><Random Number Generators> to get menu on the left. Click on ‘Set Starting Point’ and on ‘Fixed Value’. And type in the last four digits of your library card as your unique ‘Value’. (e.g. below assumes the last four digits are 4 3 2 1):
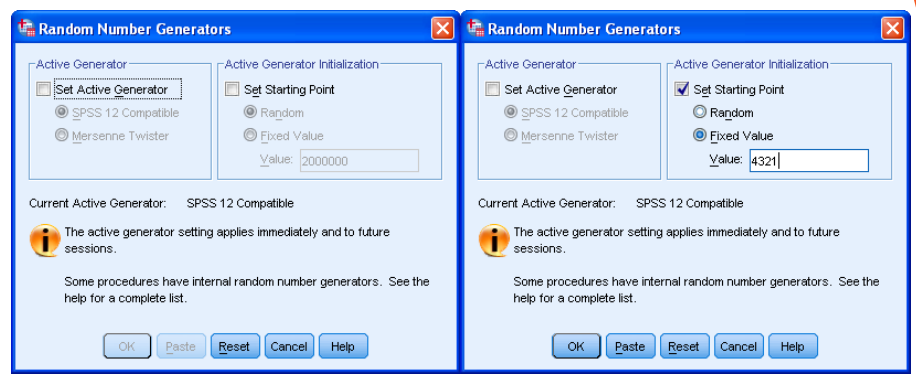
Click on [OK].
TASK 1: 统计方法代写
The SPSS data file ‘TravelDistances.sav’ contains the distances (miles) that a population of 10,000 people travel to work.
You are interested to know the average travel distance of this whole population, but it is much too expensive for you to gather all this data. Instead you are going to have to do make do with a sample in order to estimate the population average.
- Open the data file in SPSS.
- Use <Data><Select Cases> to get:
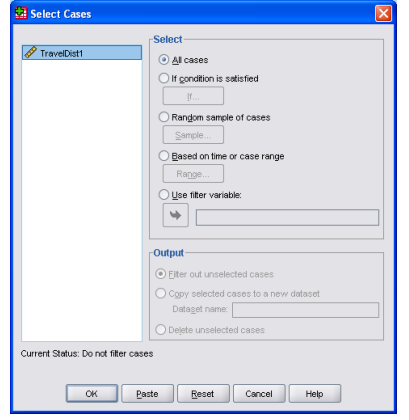
3.Highlight [Random sample of cases], and then click on [Sample] to get the menu on the left below.
4.Suppose you can afford to take a sample of size 50. In this case you want exactly 50 cases from the full sample, i.e. from the first 10,000 cases, so set as:
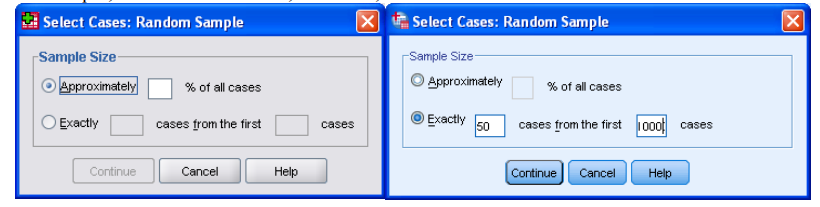
- And click on [Continue] to get menu on the left.
- Now tell SPSS that you want the sample cases putting in a fresh file, as below, where I have chosen to call my new data file ‘Sample50’:
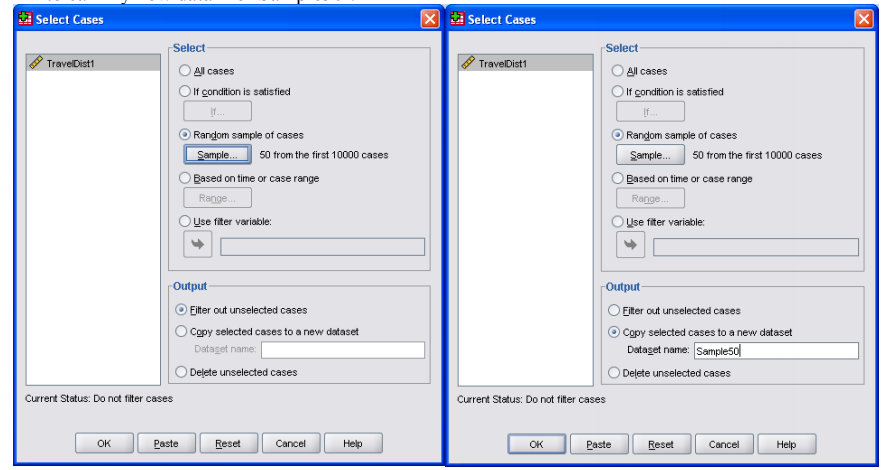
- Click on [OK]. This creates a new data file containing only 50 records – make sure you are looking at the correct file.
-
Now get SPSS to draw a histogram of your sample of data to get an initial feel for the data from which your sample is drawn. 统计方法代写
- Use <Analyze><Descriptive Statistics><Explore> (as shown in lectures) to calculate the 75% (you need to reset the default value of 95% using the [statistics] button) confidence interval for the population mean travel distance. You should get something like:
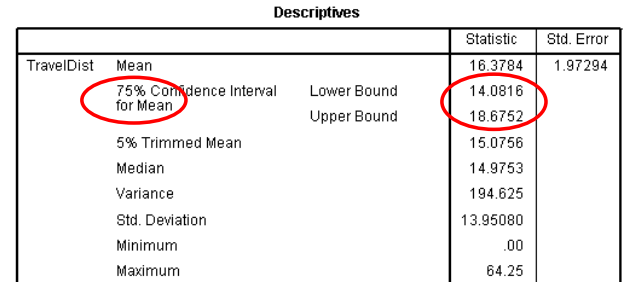

Q1: What is the chance that your confidence interval contains the true value of the mean?
Q2: The true value is 18.6 miles. Does your 75% CI contain the true value?
Q3: How many people in your workshop group do you think will have produced a 75% CI that contains the true value? (Check to see)
Q4: IF you were to repeat the above exercise a total of 20 times, how many times would you expect your 75% CI to contain the true value?
Q5: For your particular sample, get SPSS to calculate a 99% CI instead. Does it contain the true value?
Q6: How many people in your workshop group do you think will have produced a 99% CI that contains the true value? (Check to see)
Q7: IF you were to repeat the above exercise a total of 20 times, how many times would you expect your 99% CI to contain the true value?
Task 2: 统计方法代写
As we will see in week 4 lectures another way to investigate the mean (or any other parameter) of an underlying distribution from which we have drawn a sample is by using ‘hypothesis tests’. This task is designed to help to see the link between using ‘confidence intervals’ and using ‘hypothesis tests’.
As you will learn there are quite a number of different hypothesis testing tools, each appropriate for different circumstances. In this task we just use one of them, the ‘One sample T test’.
As we have seen so far, a confidence interval can be used. When we want to use a sample to make a statement about the value of the population mean (or some other parameter). A hypothesis test is used when someone else has already made a statement about the value of the population mean (or some other parameter). And we want to use a sample to test it out.
For example someone may claim that the ‘population mean = 20.0 miles’, in which case would be using our sample to look for evidence that this is untrue, ‘population mean ≠ 20.0 miles’. Using the standard notation of hypothesis testing, we would write this down as:
H0: Population mean = 20.0 miles versus Ha: Population mean ≠ 20.0 miles. 统计方法代写
Use the same sample as in Task 1, you can use SPSS apply the ‘One sample T test’ as follows:
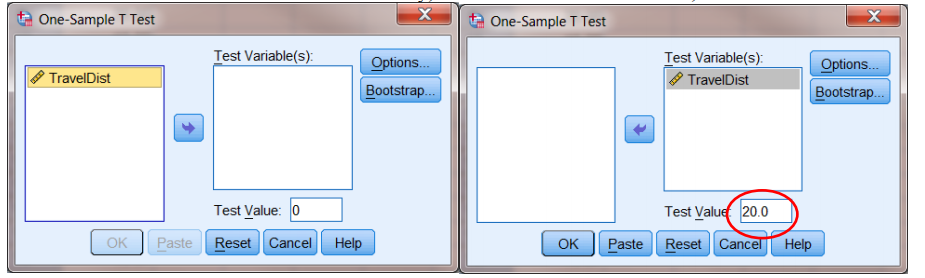
- Use <Analyze><Compare Means><One sample T test> to get the menu on the left.
- Select the Test Variable in the obvious way, and set the Test Value to 20.0, i.e.:
3.Click on [OK] to get something like:
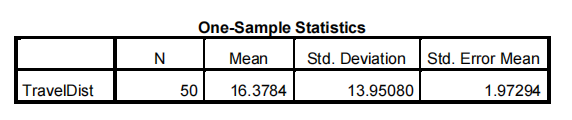
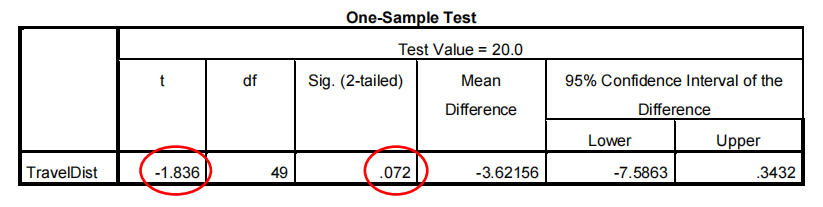
The key figures in this output are the value of the test statistic (called ‘t’ and taking the value -1.836 for my sample). And the chance of getting that value of the test statistic or something more extreme if H0 is true 统计方法代写
(called ‘Sig. (2-tailed)’ and taking the value 0.072 for my sample).
If I wish to test H0 at a 5% significance level, i.e. I am willing to take a 5% chance of being wrong, I would compare the Sig. (2-tailed) value with 0.05 and
- reject H0 IF Sig. (2-tailed) value <= 0.05
- fail to reject H0 IF Sig. (2-tailed) value > 0.05.
Hence on the evidence of my sample I would fail to reject H0
Q8: Based on your sample and your output, do you reject or fail to reject H0 (Population mean = 20.0 miles) at a 5% significance level?
Q9: Based on your sample and your output, do you reject or fail to reject H0 (Population mean = 20.0 miles) at a 25% significance level?
Q10: Based on your sample and your output, do you reject or fail to reject H0 (Population mean = 20.0 miles) at a 50% significance level?
{Record your answers on the whiteboard}
Task 3: 统计方法代写
Suppose someone else claims that the ‘population mean = 22.0 miles’. in which case would be using our sample to look for evidence that this is untrue, ‘population mean ≠ 22.0 miles’.
Repeat the hypothesis testing procedure about using your sample and report conclusions at the 5%, 25% and 50% significance levels, i.e. answers questions 11-13.
Q11: Based on your sample and your output, do you reject or fail to reject H0 (Population mean = 22.0 miles) at a 5% significance level?
Q12: Based on your sample and your output, do you reject or fail to reject H0 (Population mean = 22.0 miles) at a 25% significance level?
Q13: Based on your sample and your output, do you reject or fail to reject H0 (Population mean = 22.0 miles) at a 50% significance level?
{Record your answers on the whiteboard}
Task 4: 统计方法代写
Can you make sense of your class’s results?



